
Based on the annotation process referenced on the challenge page, I assume that the segmentation is only performed on the ROI propossed by the annotators.
But it seams that some of the segmentation are abruptly stopped at the boundary of the ROI ?
(see figure below)
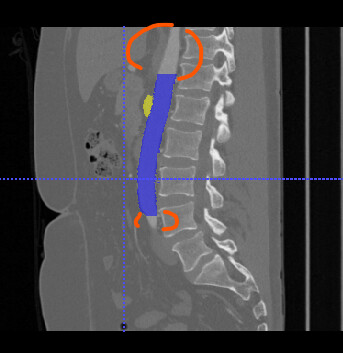
So, this could lead to ambiguous segmentation using the whole image ?